For most of the past month I was convinced the next big thing for Shiori was going to be RAG over textbook material. I had the scaffolding half-built: a documents table, a doc_chunks table, markdown ingestion that split textbook content on headings, even a range picker UI so a learner could practice over a slice of their own notes. It seemed like the obvious direction to take at the time.
Then I sat down and tried to write the part where the retrieved chunk helps the system.
I couldn’t. The grader already knows what 「〜ても」 means — that’s exactly what a frontier LLM is good at. Pulling in a textbook paragraph that re-explains 「〜ても」 doesn’t make grading more accurate; it just adds a few hundred tokens of duplicated training data with a tone mismatch. The retrieved chunk wasn’t load-bearing. It was noise dressed up as context.
That realization led me to the same question from the opposite direction: what does the system actually have access to that an LLM can’t already know? The answer is small but specific. It has the learner’s own history of wrong answers. Every mistake the user has ever made on this app is sitting in a SQLite table on disk, and no LLM was trained on that — only this system can surface it.
This post is about what I built once I took that seriously, and whether the embeddings actually do the job.
What “personal RAG” means here
The unit of retrieval is what I started calling a mistake card — a short text blob assembled from one wrong-answer row:
[助詞]
Prompt: このほか北海道や、東北の太平洋側で[___]1時間に30ミリ以上の…
Reference: も
User: は
Error: particle
Feedback: 助詞「も」 is needed because additional regions are being…Each card gets embedded once at write time with intfloat/multilingual-e5-base, L2-normalized, and stored as a BLOB column on the existing answer_log row. Because the vectors are normalized, “cosine similarity” collapses to a dot product. For a single learner’s volume — even a heavy user generates only thousands of mistakes a year — brute-force embeddings @ query in NumPy is more than fast enough. No vector database, no separate service, no extra moving part.
Three places this retrieval could pay off, in order of how easy each one is:
- In the grader. After scoring a new mistake, ask “have I seen this kind of mistake before?” and append a count + last-seen date to the feedback. Zero extra LLM calls.
- In free chat. When the user asks “why did I get X wrong” or “explain ~ても”, retrieve their past struggles with the same pattern and inject them as context for the tutor.
- In daily review. Replace the “summarize 12 random recent errors” prompt with HDBSCAN clusters over the user’s last 30 days, so review surfaces themes instead of recency.
The third one is what’s most interesting, but it’s also the most demanding of the embedding quality. Before committing to any of them, I wanted to know: does the embedding actually discriminate between kinds of mistakes, or does everything just collapse together because every row is “a Japanese learner attempting a fill-blank”?
Does the embedding actually work?
I backfilled 134 wrong-answer rows from my local development DB, filtered out the 28 that were prompt injections or placeholder text (idk, Wrong Answer, things like that), and ran an evaluation pass. Three charts, three different angles on the same question.
UMAP projection, colored by error type
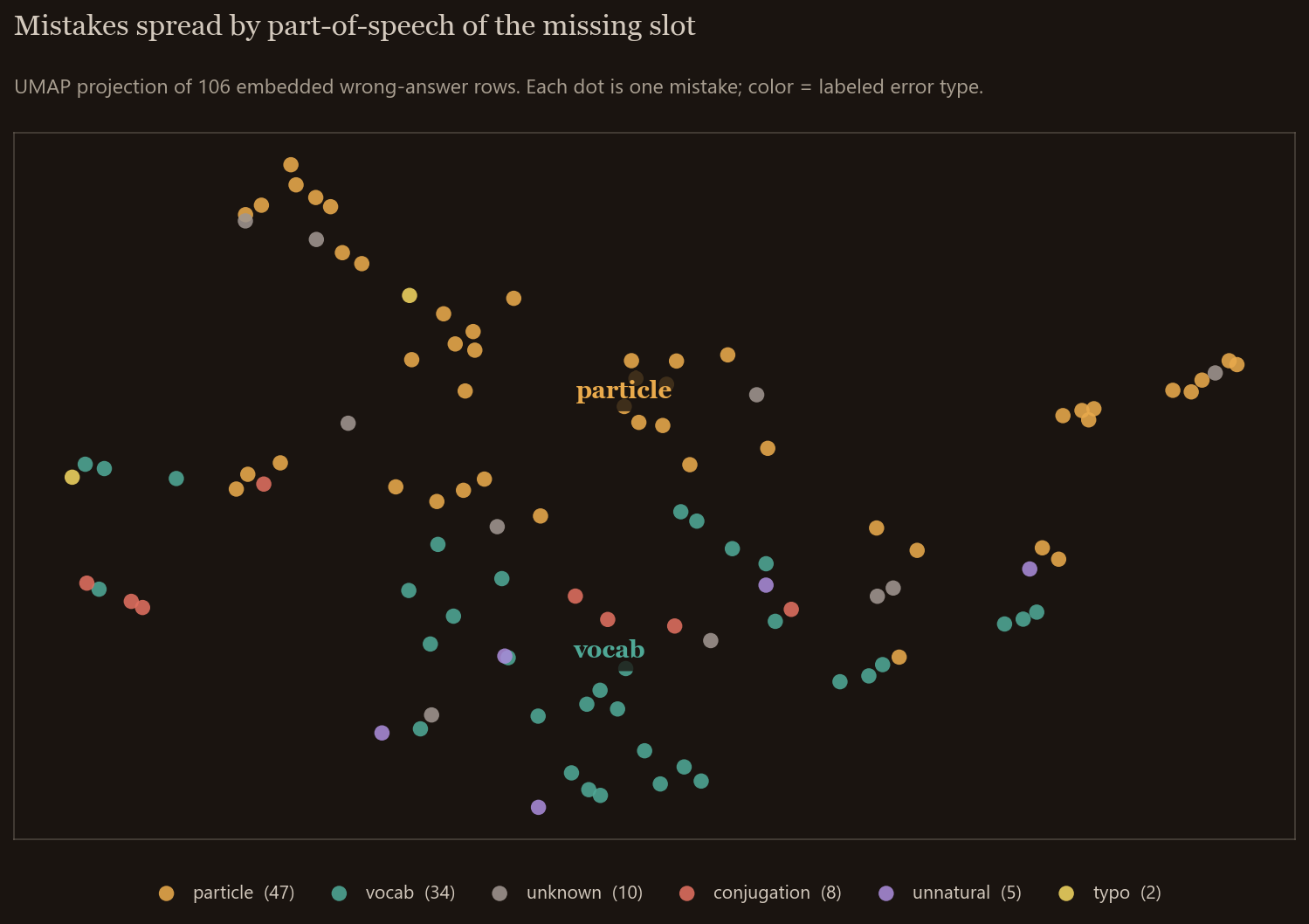
Each dot is one mistake, projected to 2D with UMAP, colored by its labeled error category. Particle mistakes (the dominant blue cloud) sit in the upper half. Vocabulary and conjugation mistakes cluster in the lower half. The separation is real but sloppy — there’s overlap, and you can find counterexamples for any rule you try to draw — but you can absolutely see that the embedding lays out grammatical mistakes differently from lexical ones.
If I’m being honest about this picture, the structure looks more like part-of-speech recovery than error-type recovery. Particles cluster because the slot the user was filling is grammatically a particle, not because the user’s confusion mode is principally about particles. That distinction matters for what comes next.
Pairwise cosine similarity, stratified
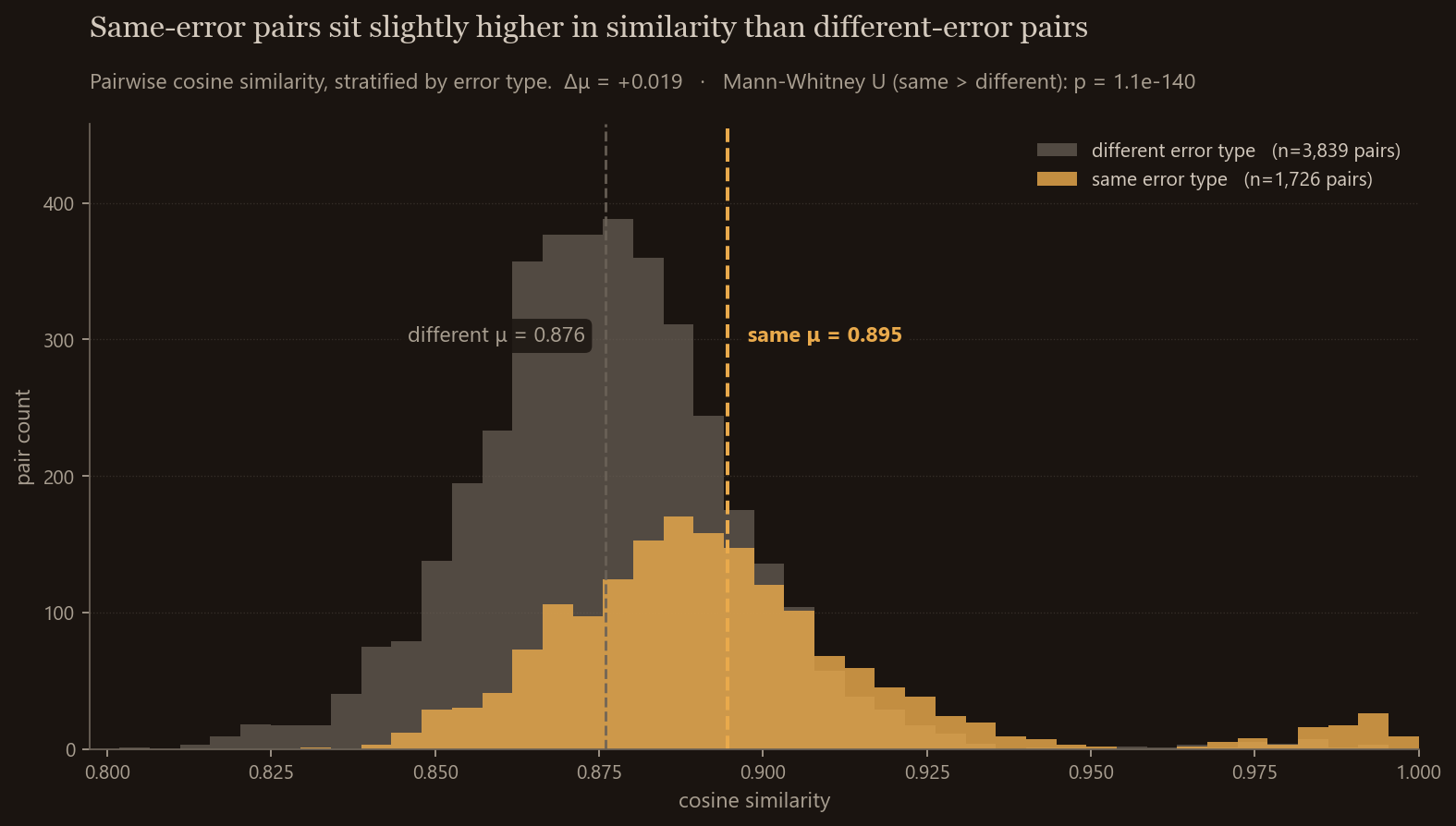
This one took me longer to read than I expected, so it’s worth explaining out loud.
Two overlapping distributions: gray is every pair of mistakes that have different error types (3,839 pairs), blue is every pair that share an error type (1,726 pairs). The first thing to notice is that everything sits in a thin band between 0.83 and 1.0. There are no learner-mistake pairs at “ordinary” embedding distances. The model thinks all of these rows are broadly similar, because they all share the scaffolding of “Japanese learner attempting a fill-blank on an NHK news exercise.” That common structure dominates before any error-type signal gets to vote.
Inside that thin band, though, the two distributions do separate. The blue mean is 0.895, the gray mean is 0.876 — a 0.019 shift. The Mann-Whitney p-value is 1.1e-140, which sounds dramatic but really just reflects that with 5,565 pairs even a tiny shift becomes statistically certain. The story isn’t “the gap is large.” It’s “the gap is real, but small in absolute terms, and the absolute floor is high.”
The asymmetric right tail on the blue distribution (pairs at 0.97+) is its own story. Those are same-prompt retries — the same exercise attempted multiple times with different wrong answers, embedded nearly identically because the prompt context is so dominant. That’s the contamination story showing up quantitatively, and we’ll see it again in a minute.
For a practical threshold — “this counts as the same kind of mistake” — somewhere around 0.92 is the natural choice. Above most cross-error pairs, below most same-error pairs. Not magic, but defensible.
Top-k retrieval precision
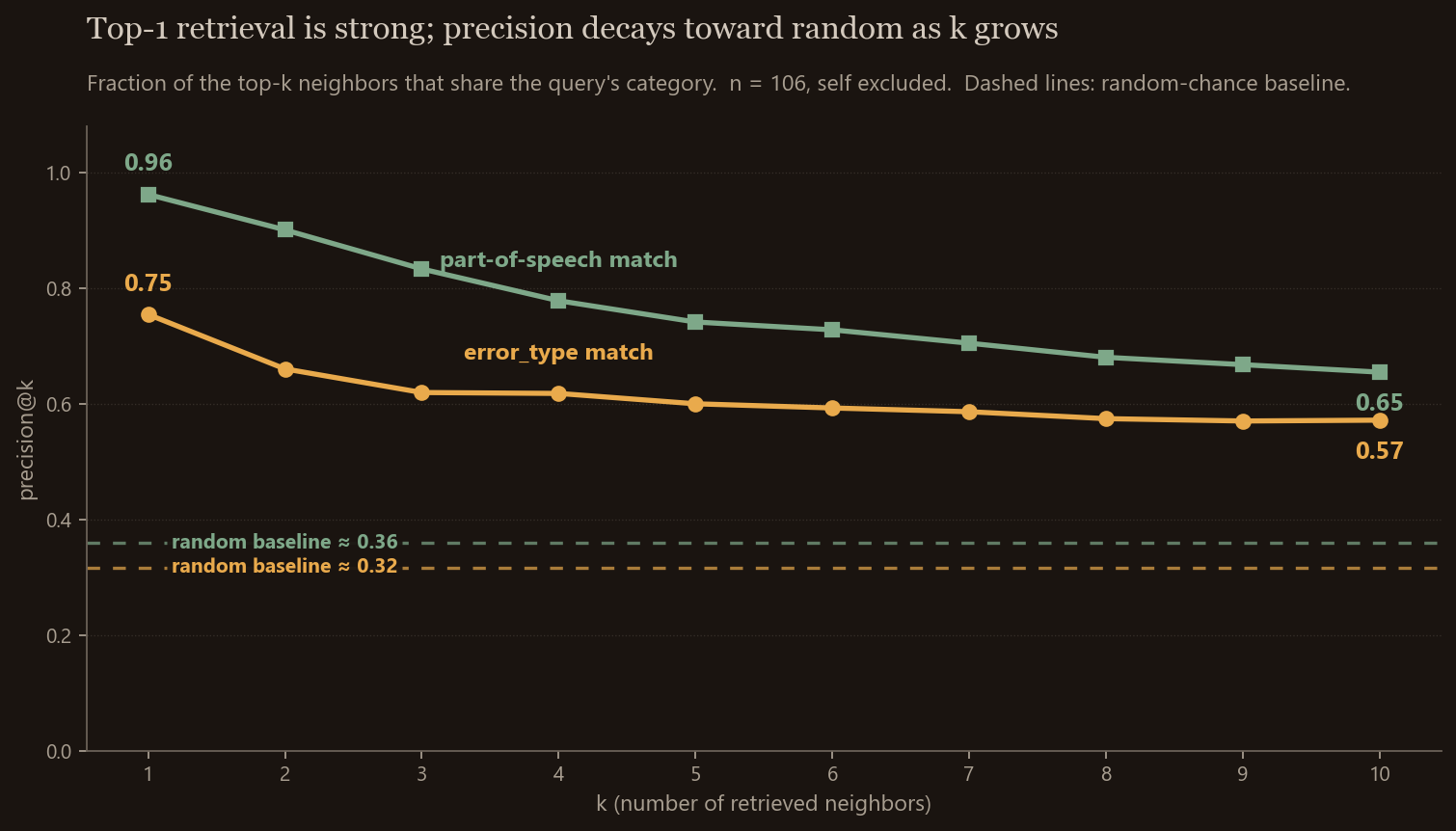
Two curves, one for whether the top-k retrieved neighbors share the query’s error_type, one for whether they share its part_of_speech. The flat dotted lines are the random baselines (what you’d get if neighbors were drawn at random).
The headline number is precision@1 = 0.75 for error type, 0.96 for POS. Three out of four “you’ve made this kind of mistake before” hits would land on a same-error-type row, and almost all of them would land on the same part-of-speech. Against a random baseline of ~0.32, that’s a real signal.
The honest caveat is the decay. By k=10, error-type precision drops to 0.57 — still meaningfully above random, but it’s no longer a strong claim. Top-1 retrieval is reliable; the broader neighborhood is noisier. This shape directly informs the integration: anything that operates on one retrieved row has the embedding’s strong side working for it. Anything that operates on a cluster — like the daily-review theming idea — has to deal with the embedding’s weaker side too.
Postscript — ablating the card
One thing nagged me after writing this section up: the card I’m embedding contains both labels I’m evaluating against. Error: particle and the [助詞] section header sit in the text the model sees, so “did the top neighbor share my error_type” is partly asking “did the top neighbor contain the same label string.” That’s not nothing — production retrieval really does benefit from those tokens — but it inflates the headline number.
I re-embedded the same 106 rows with nine card variants. The honest measurement is the clean track — cards with Error: and [POS JLPT] stripped, evaluated against the same labels. Same-exercise dedup is on, so this is the metric that matches what a deployed retrieval would actually score.
| card | err p@1 | POS p@1 |
|---|---|---|
| full (production) | 0.62 | 0.66 |
| full minus labels | 0.47 | 0.52 |
| full minus labels minus prompt | 0.73 | 0.73 |
| TF-IDF char-grams on minimal cards | 0.42 | 0.61 |
![Precision@k by card variant, with the Error: and [POS JLPT] labels left in the embedded text](/blog/shiori/ablation_with_label.png)
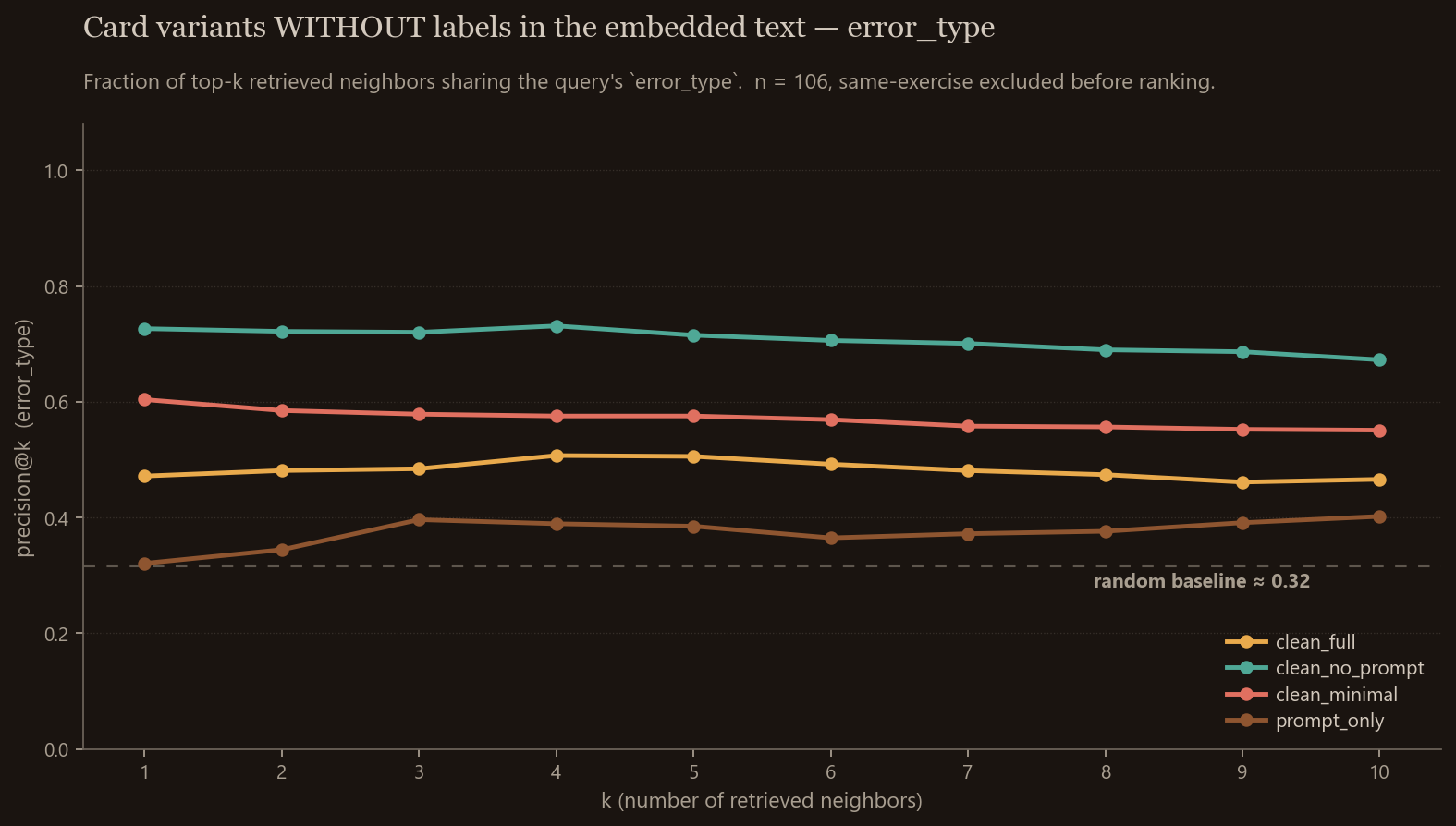
The two charts are paired by color: the variant in amber on the top chart becomes the amber line on the bottom, the teal-sage variant becomes the teal-sage line, and so on. Reading the color across both charts is how you see what each variant loses when the label tokens are taken out of its input. The brown line (prompt_only, which never had labels in it) is the same on both charts, as a sanity check.
Two things stand out. The first is that stripping the prompt is a clear win: error-type p@1 jumps from 0.47 to 0.73 on label-free cards, with the same lift on POS. The prompt was acting as noise the embedding averaged over rather than as useful context. It’s the longest text in the card by a wide margin, and cosine over a long string drags the score toward whatever the shared news article is. Once it’s gone, the remaining tokens (the user’s wrong answer, the reference, the feedback line) are densely informative, and the model can actually rank on them. The second is that e5 does beat lexical similarity on these short Japanese strings (0.73 vs 0.42 on error_type), so the embedding is doing real semantic work, just less of it than the production card suggested.
The next version of the grader annotation will use a Reference: X / User: Y / Feedback: … card, not the full-fields card I started with. Same column on the same table, just less text in it.
The good case and the failure mode
The charts give you the population view. To anchor the operational reality I ran a small mining script over the same data, looking for queries that demonstrate specific behaviors. Two examples make the point cleanly.
The clean hit. A particle query — confusion between が and に in a sentence about national renewable-energy infrastructure — pulls top neighbors that are all from different exercises, all particle mistakes, all from news on similar civic topics. (When I say “prompt” in these examples I mean the Japanese cloze sentence the learner was filling in, not an LLM prompt.)
Query:
が→に, prompt: この計画は、国[___]再生可能エネルギーの普及…
- sim=0.922 —
について→にconfusion in a recycling-roadmap article- sim=0.910 —
に→はin a school-facility funding article- sim=0.899 —
も→はin a heat-wave news report
Three different news articles, three different cloze prompts, but all “particle slot in civic-news sentences.” The embedding picked up the grammatical function across the surrounding article topics. This is what the system is supposed to do.
The failure mode. Take a single weather-news particle mistake (も→は) and look at the actual ranked retrieval:
Query:
も→は, prompt: 北海道や、東北の太平洋側で[___]1時間に30ミリ以上の激しい雨…
- sim=0.995 — same prompt, same wrong answer (retry)
- sim=0.994 — same prompt, same wrong answer (retry)
- sim=0.994 — same prompt, same wrong answer (retry)
- sim=0.993 — same prompt, same wrong answer (retry)
- sim=0.978 — same prompt, different wrong answer
- sim=0.943 — different prompt, same error type — finally
Above ~0.94, you’re just looking at the same exercise reflected back at you. The “real” retrieval — different prompts with related mistakes — starts at the 0.94 shelf. The cosine score won’t filter this for you; quite the opposite, it tells you those same-exercise rows are the most similar things in your database. If you just sort by similarity and show the top 5, you’ll show the user “you’ve made this exact mistake five times” when they only made one mistake five times in a row.
This shows up at scale, too: 9% of queries in my data have ≥3 of their top-5 from the same exercise as the query. That’s small but real, and dramatic when it happens. The operational fix is a hard WHERE exercise_id != q.exercise_id clause in the retrieval query, applied before ranking — not a post-rank cleanup.
What this means for the system
When I started this project I had two scaffolds half-built — a RAG path and an agentic-pipeline path — and I was vaguely dissatisfied with both. Manual CSV curation crowded both of them out when I needed to ship a practice feature before my exam, and for a while I worried I’d abandoned the LLM side prematurely.
What I think now, with the data above in front of me, is that I was pointing the LLM systems at the wrong problems. Drilling on hand-labeled grammar — “is the user’s まで correct here, yes or no?” — is fundamentally a labeling problem. Hand-curated CSVs beat probabilistic methods on labeling, every time. Trying to LLM-ify accuracy on a drill was never going to win.
The LLM systems pay back their complexity when they’re pointed at things CSVs can’t represent:
- Personalization over the learner’s own history — what this RAG is for. The system surfaces your particle confusions, not a textbook’s enumeration of every particle.
- Free-form interaction. Tutor chat that knows your mistake history. Role-play scenarios constrained to grammar from a specific lesson. Free composition with feedback. Cross-lesson reasoning. Anything where flexibility and adaptation beat ground-truth labels.
Each of these is the right tool for a different job inside the app. The CSV side keeps drilling honest, the personal RAG remembers, and the agent layer handles anything where flexibility matters more than a literal correct answer. The friction I’d been hitting earlier was treating them as substitutes rather than as separate components of one system.
Wiring it in
A measurement post that doesn’t end in something a user can actually see is a measurement post. So before writing this section I wired the smallest version of the feature into the running app: a disclosure on the Review your misses page that surfaces the learner’s history of similar past mistakes alongside the tutor’s note.
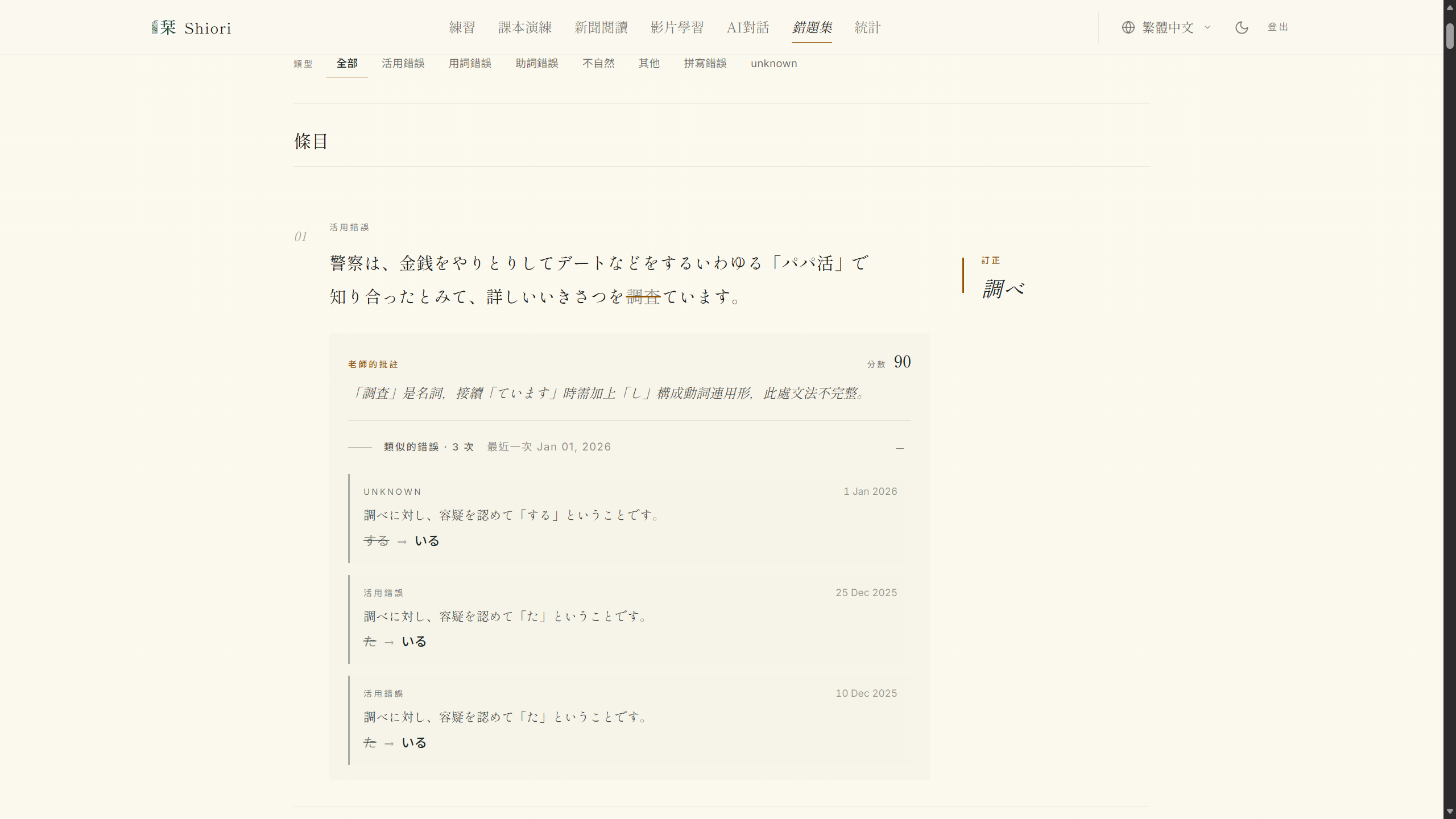
Below each tutor’s note, a quiet line reads “類似的錯誤 · 12 次 — 最近一次 May 11, 2026” when the learner’s history surfaces similar past errors. The number is one SQL fetch plus a numpy dot product against the user’s stored embeddings, threshold at 0.92, with a hard exercise_id != q.exercise_id exclusion before ranking. Clicking the line expands the top three retrieved mistakes inline (cloze prompt, wrong answer, correct answer, date), so “you’ve made this kind of mistake before” becomes a study aid the learner can actually read instead of a scolding count. The embedding column was already on the row, populated at write time, so retrieval is just a SELECT, with no extra service to operate.
Honest PoC caveats: the embeddings the live retrieval uses are still the full card format from before the ablation, not the clean_no_prompt recommendation. Re-embedding the backfill and recalibrating the threshold on the clean-card distribution is the obvious next step. The version above is real, though, running against live user data.
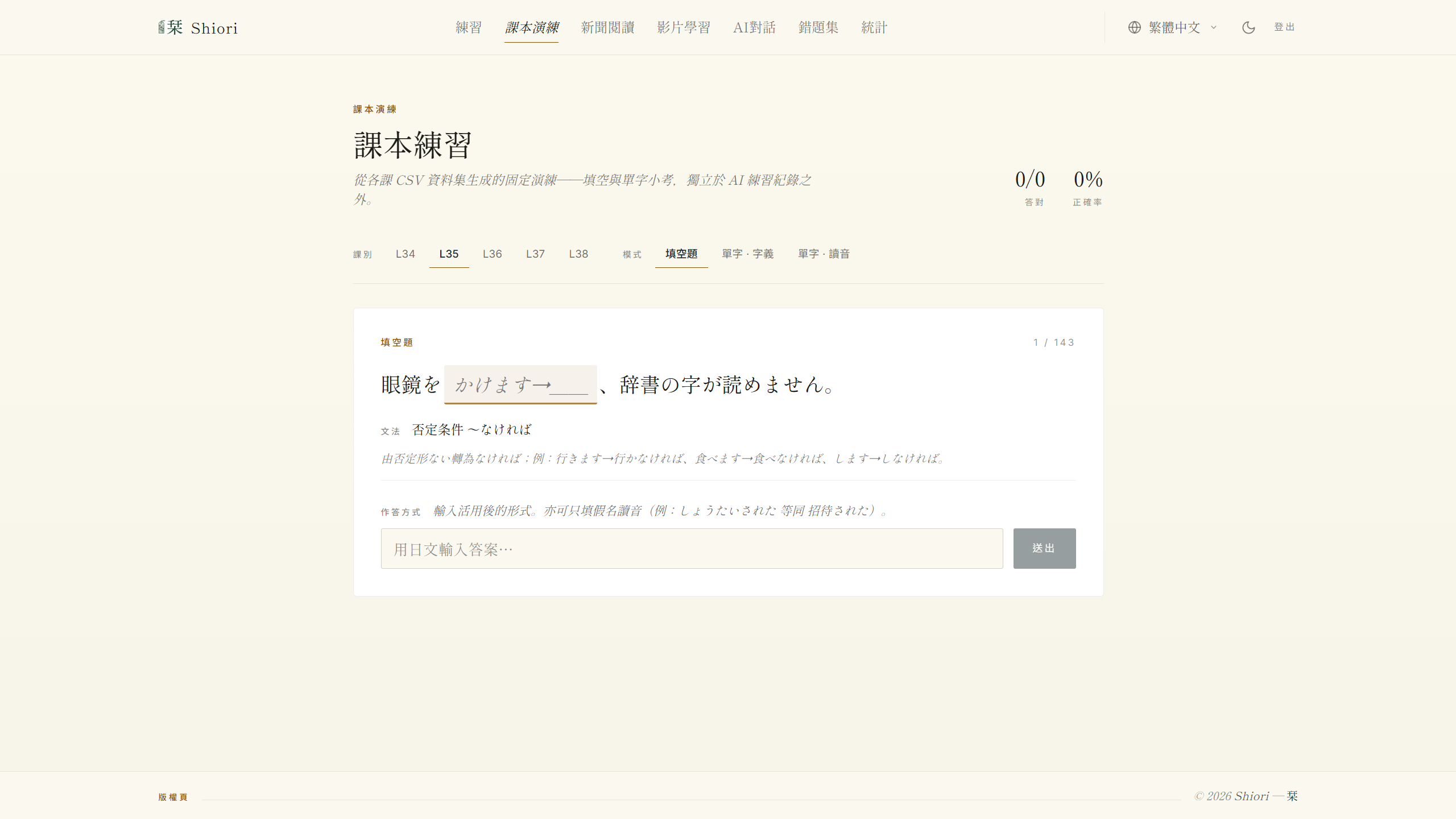
The companion view is the Practice page, which is deliberately unconnected from this RAG. It drills the learner over hand-curated lesson CSVs (fill-blanks and vocab cards from textbook lessons L34–L38) using string matching against the reference answer, with neither embeddings nor AI grading involved. The subtitle’s “separate from your AI exercise log” line is load-bearing: this is the ground-truth path that I argued earlier should stay distinct from the RAG path. (A classmate I’d shared this practice tool with claimed it saved him on our mid-term.)
What’s next
The immediate next step is finishing what the PoC defers. Re-embed the backfill with the clean_no_prompt card from the postscript, recalibrate the 0.92 threshold on the new similarity distribution (it shifts when the card gets shorter), and add the same embed-on-write call to the route that handles fresh wrong answers. Right now the live feature still leans on the original full embeddings the backfill produced. There’s no new design work in this; it’s plumbing the existing embed call into the right place.
Past the grader, the bigger question is what else the mistake-history index could be doing. It’s the only piece of Shiori with information no LLM has access to, and right now it’s only feeding a count line on the Review page. A few places it could be feeding instead:
- News-article ingestion. Shiori already turns Japanese news articles into cloze exercises, and the slot picker currently runs a uniform pass over candidate blanks. With the retrieval index it could prefer slots that match the learner’s historical confusions, so a learner who keeps tripping on も/は would see more of those particular blanks instead of random ones.
- Video comprehension questions. The video-study feature generates short comprehension questions from Japanese clips. Those could be steered toward grammar the learner has actually been weak on, rather than running uniform across viewers.
- Tutor chat. The tutor already takes a learner profile in. “You got this exact pattern wrong on Dec 28” is sharper context than “you’re weak on particles,” and the retrieval gives the system the first sentence cheaply.
Each of those is a change to feature behaviour rather than a tuning knob, and gets its own write-up as I ship it.
There are also five measurement-side threads the data above pointed at without resolving. I’ll bundle these into a single follow-up post once I’ve actually run them:
- Concept-level eval.
error_typeandpart_of_speechare labels I assigned, not what the system is trying to retrieve. Hand-labeling 30–50 retrievals as conceptually useful or not is closer to the question that matters; categorical precision@1 may even be under-estimating retrieval quality where two semantically related confusions happen to carry different tags. - Graph clustering for the daily review, instead of HDBSCAN. HDBSCAN on ~100 points in 768-dim space with a tight 0.83 similarity floor is exactly where HDBSCAN struggles, and half the clusters in my eval were noise. A similarity graph thresholded at τ ≈ 0.92 with community detection (Louvain, label propagation) probably fits this data better, and graph centrality gives “characteristic mistake” prioritisation for free.
- Recency × similarity. Cosine alone treats yesterday’s mistake and last semester’s as equally retrievable.
cos × exp(-λΔt)is one line and likely reshapes both grader counts and cluster topics meaningfully. - Cross-user variance. The “your particle confusions, not a textbook’s” claim implicitly assumes embedding regions differ per learner. All 106 rows are mine, and actually defending the claim needs cross-user data.
- More card-schema variants. This post’s ablation tested label tokens and prompt presence. Abstract cards (error pattern plus a grammatical context tag, no surface forms), feedback-only with longer feedback, and JLPT/section tags rendered as natural language rather than bracketed tokens are the next axes worth pulling.
The honest version of the original blog impulse, “I tried RAG and pivoted”, turned out to be wrong. What actually happened was “I was about to build the wrong RAG, caught it in time, and built one that retrieves over data only my system has.” That’s a better story, and one I’d happily tell again from the same direction if the data hadn’t been there to back it up.